基于大语言模型技术的铁路勘察设计档案应用研究
陈瑜
(中铁第一勘察设计院集团有限公司 ,西安 710043)
摘要:针对铁路勘察设计档案多阶段、多专业、长周期导致的归档整理瓶颈与知识利用率不足问题,探索人工智能技术的创新应用,开发了基于DeepSeek大语言模型的档案整编辅助系统,通过本地部署或VPN调用DeepSeek模型,实现自动生成主题词、分类号等元数据,显著提升档案整编效率,减少人工依赖。同时,利用RAG技术构建了接触网、供变电、信号和地质专业的试点知识库,实现知识检索、多模态对话等功能,并通过微服务架构集成至办公自动化OA系统。实践表明,DeepSeek与RAG技术的结合可有效解决档案整理效率瓶颈与知识挖掘需求,通过本地化模型降低数据安全风险,有效激活了档案价值,提升了企业设计效率和核心竞争力,为行业智能化、知识化发展奠定基础。
关键词:DeepSeek; RAG技术;大语言模型;铁路勘察设计;档案数字化
中图分类号:U29;TP399
Research on the Application of Large Language Models in Railway Survey and Design Archives
CHEN Yu
(China RAILWAY FIRST Survey and Design Institute Group Co., Ltd., Xi’an 710043,China)
Abstract:Addressing the bottlenecks in archival organization and the underutilization of knowledge caused by the multi-stage, multi-disciplinary, and long-cycle nature of railway survey and design archives, this study explores innovative applications of artificial intelligence (AI) technology. An archival compilation assistant program was developed based on DeepSeek. By deploying the DeepSeek model locally or invoking it via cloud services, the program automatically generates metadata such as subject keywords and classification codes. This significantly enhances the efficiency of archival processing and reduces reliance on manual labor.Concurrently, utilizing Retrieval-Augmented Generation (RAG) technology, pilot knowledge bases for specific disciplines including catenary, power supply and transformation, signaling, and geology were constructed. These bases enable functionalities such as knowledge retrieval, multimodal dialogue, and text generation. The system is integrated into the Office Automation (OA) system via a microservices architecture.Practice has demonstrated that the combination of DeepSeek and RAG technology effectively resolves the efficiency bottlenecks in archival organization and meets the demand for knowledge mining. The use of a localized model mitigates data security risks. This approach successfully activates the latent value of archives, enhances the enterprise's design efficiency and core competitiveness, and lays a foundation for the intelligent and knowledge-driven development of the industry.
Keywords:DeepSeek; RAG technology; Large Language Model (LLM); Railway Survey and Design; Archives Digitization
2025年初,堪比国运级别的人工智能开源大语言模型DeepSeek横空出世,某种意义上实现了科技平权和人工智能(Artificial Intelligence,AI)平权,未来还会促使AI变得像水和电一样触手可及。对于铁路勘察设计档案来说,由于铁路勘察设计项目的多阶段、多专业(40余专业协同)、长周期(5-10年)等特点,勘察设计档案的收集整理一直是瓶颈所在,档案人员大部分精力都耗费在归档整理环节。另外,作为核心知识资产的铁路勘察设计档案,其利用率直接影响企业设计效率,拥有的巨大价值亟待激活释放[1]。
根据相关研究,以及大语言模型(Large Language Model,LLM)的多模态语义解析能力等技术特性,AI可以赋能档案加工环节和档案利用等环节[2-3]。对于档案加工,主要是围绕“归档、整理、著录、鉴定”等档案业务场景展开应用,具体的应用形式表现为既有档案管理系统的AI加强或AI智能体的引入[4]。档案利用环节主要是以知识激活导向的档案内容大模型(行业大模型)开发与应用,通过深入挖掘档案所承载的内容,完成决策分析、产品开发、文档写作等多场景任务[5]。
1 基于DeepSeek的档案整编应用实践
1.1 档案整编辅助系统的设计和实现
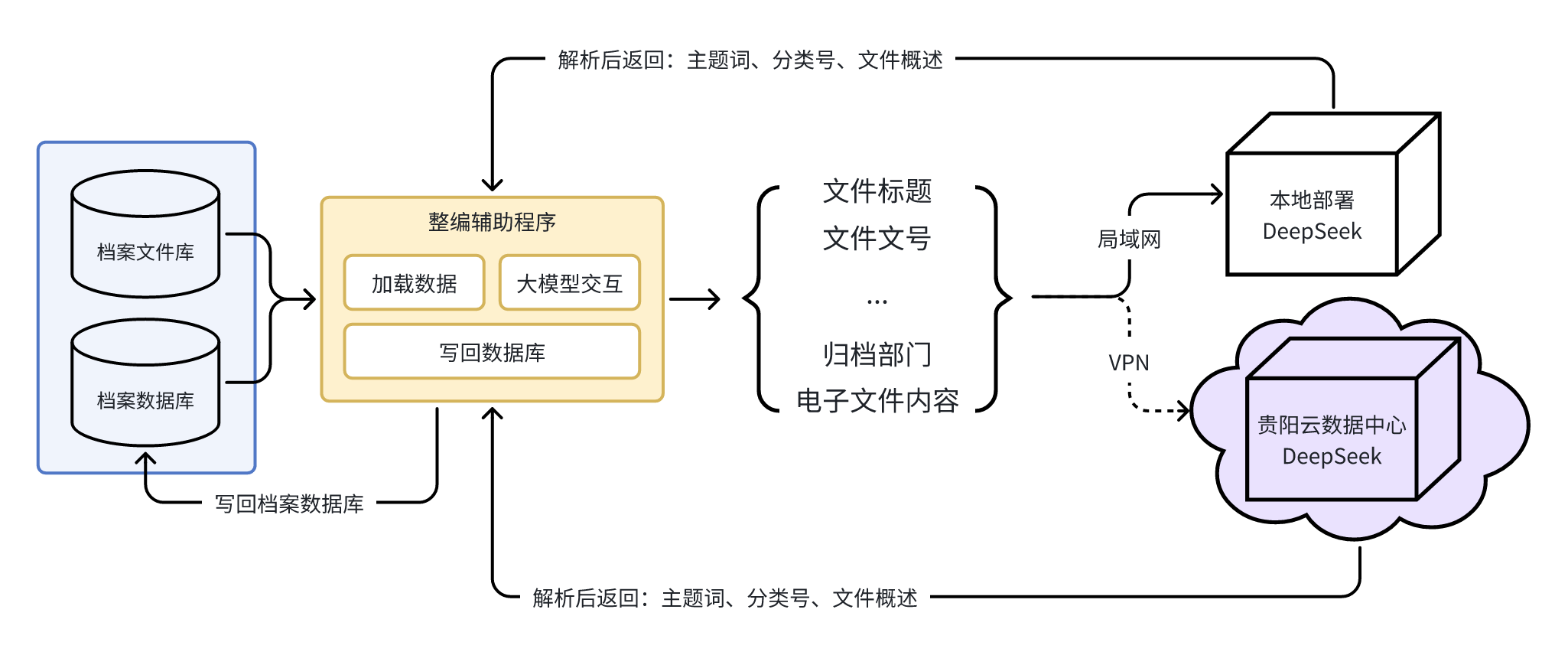
图1 档案整编辅助系统框架
如上图所示(见图1),利用python开发语言,开发“档案整编辅助系统”,通过调用本地部署DeepSeek,或利用VPN方式调用中国铁建贵阳云数据中心的满血版DeepSeek,实现辅助文书档案整编的效果。具体步骤如下:
第一步骤是加载档案数据。“档案整编辅助系统”通过连接档案数据库和档案文件库,获得待整理档案的“文件标题、文件文号、归档部门、电子文件内容、唯一ID”等关键信息,目的是利用大语言模型对自然语言处理的优势,通过这些信息获得主题词、分类号、文件文件概述等信息[6]。
第二步骤是与大模型交互。“档案整编辅助系统”将“文件标题、文件文号、电子文件内容”等信息发送给本地部署DeepSeek大模型,或利用虚拟专用网络(Virtual Private Network,VPN)安全方式调用中国铁建贵阳云数据中心的满血版DeepSeek,同时附加提示词“请根据以下文件信息,生成**主题词**和**分类号**;要求:1. 主题词:3-5 个关键词,用逗号分隔。 2. 分类号:符合《中国档案分类法》标准格式。”(见图2)。
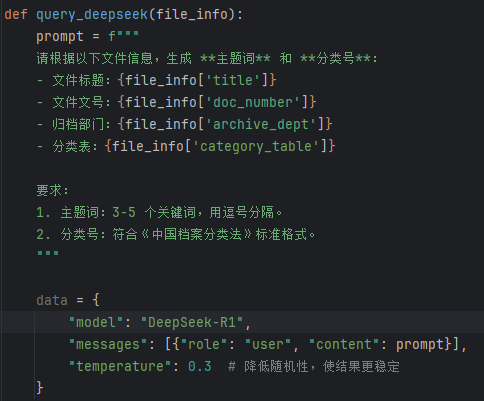
图2 向DeepSeek大模型提交的数据结构
用正则表达式或字符串处理方法,解析DeepSeek 返回的数据,提取主题词、分类号等结构化数据。
第三步骤是写回档案数据库。“档案整编辅助系统”和档案数据库建立连接,根据档案的唯一ID,将解析后的主题词、分类号等信息更新至档案数据库。
1.2 应用效果
对于传统工作方式下的文书档案,一般是通过数据接口将收发文数据从OA系统转入整编库,再进行人工整理校核后进入档案库,过程中有大量的重复性手工操作。通过DeepSeek加持的档案整编辅助系统,该过程自动化处理速度提升明显,而且减少了人工依赖,降低工作强度,也为后续的智能检索、知识管理打下基础。
2 基于RAG技术的铁路勘察设计专业试点知识库实践
铁路工程勘察设计、科研创新等活动中形成的科技档案,是铁路建设的重要技术支撑和知识资产。为了发挥其价值,本次选取接触网、供变电、信号、地质四个典型专业场景,利用检索增强生成技术(Retrieval-Augmented Generation,RAG),构建一个铁路勘察设计专业试点知识库系统[7],可提供知识检索、多模态对话、文本生成等功能。
2.1 RAG技术的核心优势和核心环节
RAG技术是目前大模型领域的一个热门方向,它是一种“检索+生成”的组合,它打破了传统大模型仅依赖自身参数预测输出的限制,通过引入外部知识库并能从海量的外部知识中挖出有用的信息,再借助大语言模型的语言天赋,把这些信息整理成清晰、自然的回答,解决了大模型在知识准确性、上下文理解以及对最新信息的利用等方面的难题,而且这种增强的生成能力使得大模型能够更好地适应各种复杂场景和任务需求[8]。RAG技术的核心环节主要包括索引、检索和生成三个部分:
一是索引核心环节。将文档拆分成块,编码成向量,并存储在向量数据库中,这一步骤是为了将大量的外部数据组织成可检索的形式。其中分片和存储是 RAG 成功的关键,分片太大会导致检索不精确,分片太小又可能丢失上下文。
二是检索核心环节。根据语义相似性,从大量数据中找到与查询最相关的信息。常用的检索方法包括关键词检索和向量检索,如BM25算法和BERT、DPR等。
三是生成核心环节。将原始问题和检索到的相关信息一起输入到大语言模型中,生成最终的答案,并确保生成的内容准确、相关且流畅自然。这是 RAG 系统的核心产出阶段。
2.2 铁路勘察设计专业试点知识库的架构
铁路勘察设计专业试点知识库的架构图主要划分为四部分:应用层、调度层、组件层以及基建层[9](见图3)。
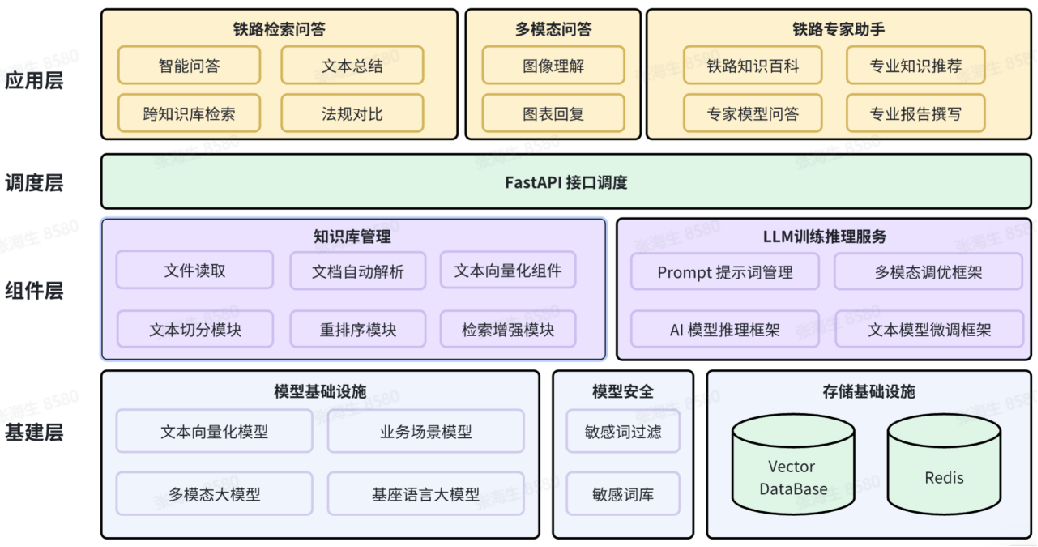
图3 铁路勘察设计专业试点知识库
应用层面向实际用户,关注于模型的实际应用场景。如智能问答、文本总结、图像理解、专业知识推荐等。系统能够处理的多种任务类型,从文本处理到图像理解,再到特定领域的知识库应用。初期系统要实现的功能有铁路检索问答、多模态问答,后期会实现专业报告撰写等高级功能。
调度层主要负责资源的分配和任务的调度,作为连接上层应用和底层的核心枢纽,该层需要确保来自应用层的模型推理、训练等请求能够得到高效、稳定的处理。该层选择了基于高性能的FastAPI异步Web框架,通过异步处理、任务队列和第三方调度库实现任务的可靠传输与均衡分配,确保模型能够高效地处理来自应用层的请求。
组件层包含了实现模型功能所需的各种组件和模块,如知识库管理和大语言模型LLM训练推理服务,组件间协同工作,实现了文本读取、文档自动解析、文本向量化、文本切分、重排序、模型推理等关键功能。
基建层是模型架构的基础,其核心使命是为上层应用提供稳定、高效且安全的底层资源与支持,包括模型基础设施、模型安全、存储基础设施。存储基础设施又包括向量数据Vector Database、内存数据结构存储系统Redis。
2.3 构建铁路勘察设计专业试点知识库的步骤
第一步骤是进行数据收集整理。利用科技档案中归档的勘察报告、施工日志、标准规范文档等文档数据,文档格式包括word、pdf、图片等,搜集了具有典型示范效果的接触网、供变电、信号、地质专业的技术文档资源200余份,数据规模达4.7GB。又采用数据清洗技术对异构数据进行标准化处理,构建包含专业语料的标准数据集,并建立动态数据更新机制,确保数据集的时效性和完备性。
第二步骤开展知识库构建及模型训练开发。通过对现有设计知识的文档进行拆分,细化为更小颗粒度的知识点,统一储存到知识底层,形成新的行业知识库。在此基础上,融合检索增强生成RAG技术架构,利用大模型摘要增强检索能力,对清洗后的样本数据进行模型训练工作,同时优化模型并行推理框架,提升系统在高并发场景下的服务响应效率[10]。
第三步骤进行接触网、供变电、信号、地质专业知识回答助手的开发集成工作。基于前两阶段构建的标准数据集和专业知识库,开发了专业智能问答助手。各个专业知识回答助手的开发采用微服务架构,专注于内部实现,通过API网关集成各专业模块,实现跨领域知识协同响应。在测试环节,进行了单元测试验证核心算法准确性,重点测试RAG模型在专业术语识别、多跳推理等方面的表现。针对测试中发现的信号专业标准条文更新滞后问题,通过动态数据更新机制实时同步了最新。目前以上功能已部署集成至我院OA系统,日均访问量100余次,成为工程设计人员的重要智能辅助工具(见图4)。

图4专业知识问答助手集成于OA系统
第四步骤推进系统测试与更新优化。由接触网、供变电、信号、地质四个专业技术人员对专业知识回答助手进行功能测试,通过询问专业问题,专业知识回答助手生成答案,同时专业技术人员对答案进行正确性检查确认,对每个回答按照内容准确程度进行1-5分打分,最终形成近3000个专业问题测试集。通过用户测试,重点评估系统的知识覆盖度、答案准确性等核心指标的表现,对错误案例进行溯源分析,持续优化知识向量表示和推理决策模型。
表1:接触网、供变电、信号、地质四个专业资料数量及测试情况表
供变电、接触网专业 | 信号专业 | 地质专业 | |
问题总数量 | 1220 | 805 | 940 |
回答正确(5分) | 1001 | 520 | 733 |
回答错误(1-3分) | 129 | 94 | 101 |
答非所问(0分) | 54 | 26 | 43 |
未覆盖问题 | 36 | 165 | 63 |
准确率(%) | 84.54% | 81.25% | 83.58% |
如上表所示,未覆盖问题是指不在模型库检索范围之内,准确率的计算是回答正确数量/(问题总数量-未覆盖问题数量)。
2.4 应用效果
信号专业知识问答助手可实现知识检索与问答能力,能够高效地处理包含表格、图片在内的多种数据类型,实现跨模态的知识融合与推理。同时通过精准的校准机制,确保输出的信息符合提供的文档规范和专业标准。实现核心功能6项,包括文档数据导入、数据清洗分段、文档状态管理、知识库选择、识图描述及回答返回图片。对相似问题具有泛化性,支持单轮及多轮对话、流式对话输出。支持用户输入专业图片,系统对知识库进行查询,输出返回对图片内容的解释。
地质专业知识回答助手能够准确理解各阶段设计说明、设计方案、技术规格书、专题研究报告、变更文档、项目总结报告、咨询报告等经典历史数据、标准规范、法律法规、图例、公式、表格等各类知识和规则,具备逻辑思维能力,能够根据已有知识和规则进行解析回答。支持用户对多知识库进行查询,对内容进行总结,同时根据知识库从属以不同窗口罗列召回结果,输入用户与知识库内容相关的问题,输出从不同标准规范文段中摘取的文段并进行总结,最后罗列出引用的标准规范出处(见图5)。
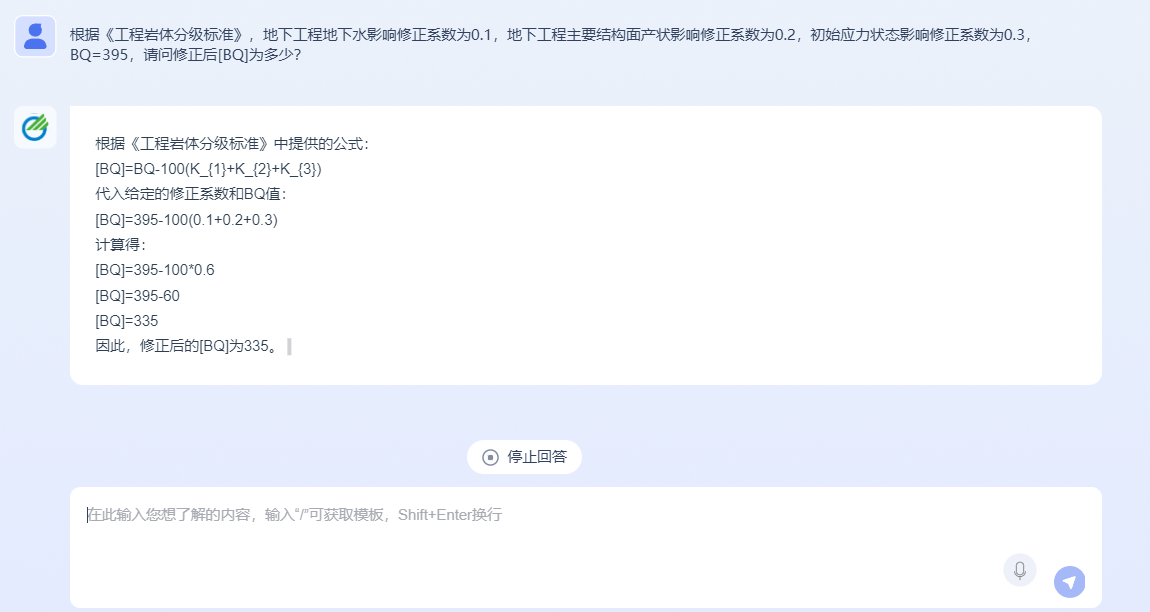
图5地质专业知识回答助手运行图
3 结束语
开源大语言模型DeepSeek的崛起,使得大模型技术不再高高在上,普通技术人员也可以本地部署研究学习,更为铁路勘察设计档案业务带来了革命性的变革机会,通过本地化部署的大模型和RAG技术结合,进一步解决了企业在档案知识挖掘利用安全方面的顾虑。通过此次实践表明,AI技术能够有效激活档案价值,提升企业核心竞争力。未来,随着大模型技术的持续优化与行业数据的不断积累,铁路勘察设计档案业务将进一步向智能化、知识化、集成化方向发展,我们将继续探索大模型在档案业务中的创新应用,为铁路勘察设计行业的高质量发展注入新动能。
参考文献
[1]王韵哲,江若飞,俞佳.铁路建设项目数字档案系统构建研究[J].铁路技术创新,2024,(02):29-34.DOI:10.19550/j.issn.1672-061x.
2023.11.13.001.
[2]张莹,李春红,郭祥,等.人工智能在铁路工程档案管理中的应用[J].铁路技术创新,2023,(04):84-87.DOI:10.19550/j.issn.
1672-061x.2023.06.02.003.
[3]刘越男,钱毅,王平,等.挑战与展望:DeepSeek对档案工作的影响及应用前景[J].浙江档案,2025,(02):5-13.DOI:10.16033/
j.cnki.33-1055/g2.20250305.001.
[4]林空.大语言模型技术赋能档案数字资源治理转型:路径方法与应用场景[J].浙江档案,2025,(03):11-15.DOI:10.16033/
j.cnki.33-1055/g2.20250325.002.
[5]杨建梁,郑梦霏,杨格秀.DeepSeek在档案管理领域中的应用与展望[J].机电兵船档,2025,(01):2-3+25.
[6]郭祥,乔立贤,李春红,等.基于业务系统的电子档案在南宁北站建设中的应用[J].铁路技术创新,2023,(04):102-109.DOI:10.19550/
j.issn.1672-061x.2023.04.10.002.
[7]童欣,方燃.勘察设计企业知识管理转型升级的实践与探索[J].中国勘察设计,2024,(06):12-14.
[8]刘洋.“大模型+RAG”技术在档案工作中的应用探析[J].中国档案,2025,(03):64-65.
[9]王康.面向铁路线路维修的数字化智能分析软件研发与应用[J].铁路技术创新,2025,(01):106-113.DOI:10.19550/
j.issn.1672-061x.2024.10.14.022.
[10]于松伟,刘巍,夏秀江,等.基于知识图谱的城轨大模型RAG检索增强知识库构建研究[J/OL].都市快轨交通,1-8[2025-04-12].
http://kns.cnki.net/kcms/detail/11.5144.U.20250402.1928.004.html.
通信作者:陈瑜
地址:陕西省西安市西影路铁一院,710043
联系电话:15829006512
E-mail:cy9812@163.com
第一作者:陈瑜,高级工程师。